这玩意会持续更新,因为太多了。
0.定义
线段树是一种可以很方便的维护区间信息的 DS,是一种Leafy Tree。
线段树的一个结点是维护的原序列的一段区间的信息。具体结构是一棵完全二叉树,若一个结点维护的是 的信息,设 则根结点的左儿子维护的就是 ,右儿子维护的是 的信息。
结点需要用 pushup 操作来合并信息,由于是分两块计算,所以维护的东西必须有结合律,更准确的说,维护的信息必须是个幺半群,即需要有结合律,有单位元。
一般设根结点的下标为 rt,则左子树的下标为 rt * 2 = rt << 1,右子树的下标为 rt * 2 + 1 = rt << 1 | 1。
结构体如下:
struct Rukkhadevata{ int l,r; Info...; // Lazytag...;}tree[MAXN << 2];inline void pushup(int rt){ tree[rt].info = merge(tree[rt << 1].info,tree[rt << 1 | 1].info);}inline void pushdown(int rt){ if(available(tree[rt].laz)) { Operation(rt << 1,tree[rt].laz); Operation(rt << 1 | 1,tree[rt].laz); reset(tree[rt].laz); }}需要注意,这种堆式存储要开 4 倍空间。
1.操作
建树
我们递归的处理每个区间,对每个结点分配边界,如果是叶子结点就分配信息,在回溯的时候执行 pushup 合并信息。
inline void build(int l,int r,int rt){ tree[rt].l = l,tree[rt].r = r; if(l == r) { tree[rt].info = origin[l]; return ; } int mid = (l + r) >> 1; build(l,mid,rt << 1); build(mid + 1,r,rt << 1 | 1); pushup(rt);}区间修改类
我们需要维护一个 lazytag,具体的,就是直接给一个子树的根结点打标记,不直接修改,等需要查询子区间的时候再 pushdown 下去。不同的 lazytag 间可能相互有影响,需要根据维护的信息适时下放标记。
然后我们需要递归区间,分三种情况:
- 修改区间完全包含现区间,则直接打标记。
- 修改区间和现区间的左半部分有交集,就递归向左子树走。
- 修改区间和现区间的右半部分有交集,就递归向右子树走。
模板代码如下:
inline void modify(int l,int r,int rt,int val){ if(l <= tree[rt].l && r >= tree[rt].r) { Operation(rt,val); return ; } // pushdown(rt); int mid = (tree[rt].l + tree[rt].r) >> 1; if(l <= mid) modify(l,r,rt << 1,val); if(r > mid) modify(l,r,rt << 1 | 1,val); pushup(rt);}区间查询类
还是一样的,注意准备前往子结点的时候需要下传标记。
inline int query(int l,int r,int rt){ if(l <= tree[rt].l && r >= tree[rt].r) return tree[rt].val; // pushdown(rt); int mid = (tree[rt].l + tree[rt].r) >> 1,res = identity(); if(l <= mid) Operation(res,query(l,r,rt << 1)); if(r > mid) Operation(res,query(l,r,rt << 1 | 1)); return res;}2.权值线段树
类似权值树状数组,可以查询全局 小值,查询排名等,在某些时候可以代替平衡树。
小值可以线段树上二分,排名就是直接一个前缀和。
3.动态开点线段树
有的时候,题目不允许我们使用堆式存储开线段树,又不能离散化的时候,我们就可以使用动态开点的方式。具体的,就是刚开始只有一个管辖 的根结点,等需要用的时候才开这个点。
因为每次操作最多创建 个结点,所以最后的空间复杂度可以从 优化到 。
结构体会有些变化:
struct Rukkhadevata{ int ls,rs; int l,r; // 其实可以不计 Info...; // Lazytag...;}tree[MAXQ * LOGN];#define lson tree[rt].ls#define rson tree[rt].rs需要多加一个 newNode 操作,你也可以选择不加。这怎么一股平衡树味
inline int newNode(int l,int r,int val){ ++cnt; tree[cnt].l = l,tree[cnt].r = r,tree[cnt].val = val,tree[cnt].ls = tree[cnt].rs = 0; return cnt;}因为不需要初始化所有结点,所以我们可以省略建树操作。相应的,别的操作也需要一些修改。
inline void pushup(int rt){ tree[rt].val = merge(tree[lson].val,tree[rson].val);}inline void pushdown(int rt){ if(tree[rt].laz) { if(lson) Operation(lson,tree[rt].laz); if(rson) Operation(rson,tree[rt].laz); reset(tree[rt].laz); }}inline void modify(int &rt,int l,int r,int L,int R,int val){ if(!rt) rt = newNode(l,r,val); if(L <= l && R >= r) { Operation(rt,val); return ; } int mid = (l + r) >> 1; if(L <= mid) modify(lson,l,mid,L,R,val); if(R > mid) modify(rson,mid + 1,r,L,R,val); pushup(rt);}inline int query(int rt,int l,int r,int L,int R){ if(!rt) return 0; if(L <= l && R >= r) return tree[rt].val; int mid = (l + r) >> 1,res = identity(); if(L <= mid) Operation(res,query(lson,l,mid,L,R)); if(R > mid) Operation(res,query(rson,mid + 1,r,L,R)); return res;}4.势能线段树
lazytag 的需求就是可以合并,并且可以更新子结点。但是有的操作就不满足,比如区间开根。
但是,我们惊奇的发现,区间开根对 和 没有贡献。所以,我们可以维护区间最大值,若最大值 则直接返回,否则接着向下走。
也因此,我们可以维护区间历史最值,区间取 min/max 等操作,而这就是吉司机线段树。
5.李超线段树
这是真“线段”树
这个线段树是用来维护线段的最高/最低点的,并且可以支持插入线段。
每个结点维护的是一段区间内的最优线段,就是这个线段在区间中点处的 值是最大的线段。
这个东西的核心就在分类讨论,具体如下:
- 新线段完全覆盖老线段,则直接修改,返回。
- 老线段完全覆盖新线段,则直接返回。
- 刚好交于中点,归于新线段不如老线段。
- 这写不下,往下看。
如果 新线段 优于老线段 ,就先交换一下,我们考虑中点处 不如 优的情况。
- 若左端点 优于 ,则交点会在左区间,前往左儿子处理。
- 若右端点 优于 ,则交点会在右区间,前往右儿子处理。
- 如果都不优,则直接返回。
或者还有一种比较斜率的办法:
- 若 的斜率小于 ,则比较中点的 坐标,若 小于 则前往右儿子更新 ,否则前往左儿子更新 。
- 若 的斜率大于 ,且中点坐标 小于 ,则前往左儿子更新 ,否则前右儿子更新 。
- 斜率一致那比较截距, 优于 就更新。
查询就很简单,枚举所有可能包含 的线段,然后取极值。
模板代码如下(不含线段拆分,给斜率优化用的那种):
namespace LiChaoSGT{ struct Rukkhadevata { int ls,rs,seg; }tree[MAXN]; int k[MAXN],b[MAXN]; inline int F(int id,int x) {return k[id] * x + b[id];} int cnt,root; inline void insert(int &rt,int l,int r,int S) { if(!rt) tree[rt = ++cnt].seg = S; else { if(l == r) { if(F(S,l) < F(tree[rt].seg,l)) tree[rt].seg = S; return ; } int mid = (l + r) >> 1; if(F(S,mid) < F(tree[rt].seg,mid)) swap(S,tree[rt].seg); if(F(S,l) < F(tree[rt].seg,l)) insert(tree[rt].ls,l,mid,S); if(F(S,r) < F(tree[rt].seg,r)) insert(tree[rt].rs,mid + 1,r,S); } } inline int query(int rt,int l,int r,int p) { if(!rt) return LONG_LONG_MAX; if(l == r) return F(tree[rt].seg,p); int mid = (l + r) >> 1; return min(F(tree[rt].seg,p),(p <= mid) ? query(tree[rt].ls,l,mid,p) : query(tree[rt].rs,mid + 1,r,p)); }}6.可持久化
这玩意分两种,但维护都差不多(我感觉可持久化数据结构的变化都挺像的)
可持久化线段树
我喜欢叫可持久化数组。
我们先思考,怎么暴力可持久化。
这不简单,直接复制
是,但是空间立刻爆炸。
我们发现,每次修改,最多会访问 个结点,如下图:
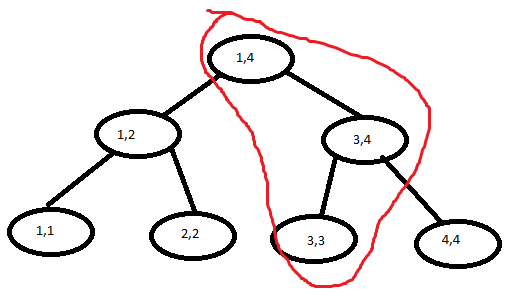
所以,我们可以考虑只将这一条链复制下来,和原来的线段树共用一些结点,对每个版本,把根结点存下来就好了。
其实懂了以后就不难写出代码,这里贴一个模板题↗的:
namespace PersistentSGT{ struct Nahida { int ls,rs,val; }tree[MAXN << 5]; int cnt,root[MAXN]; inline int newNode(int node) { ++cnt; tree[cnt] = tree[node]; return cnt; } inline int build(int rt,int l,int r) { rt = ++cnt; if(l == r) { tree[rt].val = a[l]; return cnt; } int mid = (l + r) >> 1; tree[rt].ls = build(tree[rt].ls,l,mid); tree[rt].rs = build(tree[rt].rs,mid + 1,r); return rt; } inline int update(int rt,int l,int r,int pos,int val) { rt = newNode(rt); if(l == r) tree[rt].val = val; else { int mid = (l + r) >> 1; if(pos <= mid) tree[rt].ls = update(tree[rt].ls,l,mid,pos,val); else tree[rt].rs = update(tree[rt].rs,mid + 1,r,pos,val); } return rt; } inline int query(int rt,int l,int r,int pos) { if(l == r) return tree[rt].val; int mid = (l + r) >> 1; if(pos <= mid) return query(tree[rt].ls,l,mid,pos); else return query(tree[rt].rs,mid + 1,r,pos); }}可持久化权值线段树
也叫主席树。
就是把权值线段树可持久化的产物,可以拿来解决区间 k 小值。
具体来说,先离散化,然后从左到右依次添加每个值,并且每次添加完后保存根结点,这样我们就得出了所有 的线段树,这个时候,我们可以运用差分的思想,用 的线段树减去 的线段树(每个结点对应相减),就得到了 的线段树。然后正常权值线段树查询 小值就行了。
应用
可持久化线段树可以让很多基于数组的数据结构变得可持久化,还有就是维护每次变化很小并且需要访问历史版本的信息。
主席树用处就多了去了,外层的前缀和/差分可以看作一层数据结构,因此主席树维护的是静态的二维信息,你可以把外面的换成树状数组,就可以维护动态的了。
同时,这个启发我们,权值线段树是可以“差分”的。
虽然说不强制在线可以被整体二分/CDQ 分治等离线算法吊着打,但是我就喜欢 DS。
注意
但凡是可持久化的题空间一般不会太小,除非毒瘤出题人。所以我们可以大胆一点,直接开 倍空间。
并且这个东西需要共用结点,不能写堆式存储,必须写动态开点的写法。
类似的前缀和思想在可持久化字典树也有体现。
7.标记永久化
有的时候,上面的上传/下传标记不再适用,比如写主席树和树套树的时候。
这个时候,我们干脆直接不下传标记,直接在访问某个结点的时候累加所有标记就行了。
修改会有些不同:如果操作区间完全覆盖现在的区间,则只打标记不改值,否则修改值。
可以看下面的模板,实现了区间加法:
#include <bits/stdc++.h>#define int long longusing namespace std;
constexpr int MAXN = 1e5 + 24;struct Rukkhadevata{ int val,laz;}tree[MAXN << 2];int a[MAXN];inline void build(int l,int r,int rt){ if(l == r) { tree[rt].val = a[l]; return ; } int mid = (l + r) >> 1; build(l,mid,rt << 1); build(mid + 1,r,rt << 1 | 1); tree[rt].val = tree[rt << 1].val + tree[rt << 1 | 1].val; // 建树需要 pushup 一下}inline void modify(int rt,int l,int r,int L,int R,int val){ if(L <= l && R >= r) { tree[rt].laz += val; // 完全覆盖只打标记 return ; } tree[rt].val += (R - L + 1) * val; // 否则修改值 int mid = (l + r) >> 1; if(R <= mid) modify(rt << 1,l,mid,L,R,val); else if(L > mid) modify(rt << 1 | 1,mid + 1,r,L,R,val); else modify(rt << 1,l,mid,L,mid,val),modify(rt << 1 | 1,mid + 1,r,mid + 1,R,val);}inline int query(int rt,int l,int r,int L,int R){ int res = tree[rt].laz * (R - L + 1); // 累加标记的贡献 if(L <= l && R >= r) return tree[rt].val + res; int mid = (l + r) >> 1; if(R <= mid) res += query(rt << 1,l,mid,L,R); else if(L > mid) res += query(rt << 1 | 1,mid + 1,r,L,R); else res += query(rt << 1,l,mid,L,mid) + query(rt << 1 | 1,mid + 1,r,mid + 1,R); return res;}int n,m,opt,l,r,v;signed main(){ ios::sync_with_stdio(0),cin.tie(0),cout.tie(0); cin >> n >> m; for(int i = 1;i <= n;i++) cin >> a[i]; build(1,n,1); for(int i = 1;i <= m;i++) { cin >> opt >> l >> r; if(opt == 1) { cin >> v; modify(1,1,n,l,r,v); } else cout << query(1,1,n,l,r) << "\n"; }}8.线段树维护矩阵乘法
前面我们说了,线段树维护的信息实质上是一个幺半群。
我们又发现,矩阵乘法这东西既有结合律还有单位元,所以可以放到线段树上维护。
但直接维护,显然没有什么意义,除非有毒瘤出题人出这个可爱题。
我们回过头去看P3373 线段树2↗,发现我们需要维护两个 lazytag,太烦了。
这个时候,我们维护的矩阵乘法就有用了。
我们不难发现,我们可以多此一举的做下面的操作:
然后,对于线段树的每个结点,我们考虑维护一个矩阵 ,其中 表示这个结点的值, 表示该区间长度。
我们不难构造出这个转移矩阵 ,使得我们可以将加法操作写成 。
同理,我们可以构造出一个乘法的转移矩阵 。
这个时候,我们矩阵乘法的结合律就发挥作用了。我们只用维护一个矩阵作为 lazytag,就可以了。
但是,它的作用远不止于此。
我们可以定义广义矩阵乘法如下:
懒得证明了,反正它有结合律,还有单位元为 。
我们再看这道题:P4314 CPU 监控↗。
我们可以将信息这么维护: , 表示这个位置的值, 表示历史最值。pushup 就是维护区间最值,。
因为 ,加法矩阵是长这样的:; ,覆盖矩阵是 。
然后就可以方便的维护这些操作了。
但是两个大常数的东西在一起真的不会 T 吗
这个东西可能需要一些卡常,可以用标记永久化降低常数。
动态 DP 也是基于这个原理,可以用数据结构维护。
9.吉司机线段树/Segment Beats
可以维护区间取最值操作/区间历史最值查询。
先上一道例题
给你一个序列 ,维护以下操作
- 输出
- 输出
我们发现取 很不好维护,考虑转化。
我们维护以下几个值:
区间内最大值 ,区间内严格次大值 ,区间和 ,区间内最大值个数 。
再维护以下 lazytag:
加法标记 ,取 标记
我们考虑将取 操作转化为加减法。
对于操作 ,做以下分类讨论:
- 若 ,则操作对这个区间及子区间无效,直接返回(和上面的势能线段树类似)。
- 若 ,操作会对所有的 生效,对区间和产生 的贡献,同时打标记。
- 否则,暴力向下。
这个可以通过势能分析法证明,复杂度是 的。
有些题会让你同时维护六个操作(区间 修改/查询),这种出生题码量会非常大,同时需要大力分讨。
所以吉司机线段树一个 pushup 有 多行挺正常的。
这里附一份完整代码。
BZOJ 4695,上面的六个操作的
#include <bits/stdc++.h>#define int long longusing namespace std;
constexpr int MAXN = 5e5 + 5,inf = 1e18;int n,m,opt,l,r,x,a[MAXN];struct Rukkhadevata{ int max,min,smx,smn,mxCnt,mnCnt,sum; int lazmx,lazmn,lazsm;}tree[MAXN << 2];inline void pushup(int rt){ tree[rt].sum = tree[rt << 1].sum + tree[rt << 1 | 1].sum; if(tree[rt << 1].max == tree[rt << 1 | 1].max) { tree[rt].max = tree[rt << 1].max; tree[rt].smx = max(tree[rt << 1].smx,tree[rt << 1 | 1].smx); tree[rt].mxCnt = tree[rt << 1].mxCnt + tree[rt << 1 | 1].mxCnt; } else if(tree[rt << 1].max > tree[rt << 1 | 1].max) { tree[rt].max = tree[rt << 1].max; tree[rt].smx = max(tree[rt << 1].smx,tree[rt << 1 | 1].max); tree[rt].mxCnt = tree[rt << 1].mxCnt; } else { tree[rt].max = tree[rt << 1 | 1].max; tree[rt].smx = max(tree[rt << 1].max,tree[rt << 1 | 1].smx); tree[rt].mxCnt = tree[rt << 1 | 1].mxCnt; } if(tree[rt << 1].min == tree[rt << 1 | 1].min) { tree[rt].min = tree[rt << 1].min; tree[rt].smn = min(tree[rt << 1].smn,tree[rt << 1 | 1].smn); tree[rt].mnCnt = tree[rt << 1].mnCnt + tree[rt << 1 | 1].mnCnt; } else if(tree[rt << 1].min < tree[rt << 1 | 1].min) { tree[rt].min = tree[rt << 1].min; tree[rt].smn = min(tree[rt << 1].smn,tree[rt << 1 | 1].min); tree[rt].mnCnt = tree[rt << 1].mnCnt; } else { tree[rt].min = tree[rt << 1 | 1].min; tree[rt].smn = min(tree[rt << 1].min,tree[rt << 1 | 1].smn); tree[rt].mnCnt = tree[rt << 1 | 1].mnCnt; }}inline void build(int l,int r,int rt){ tree[rt].lazmn = inf,tree[rt].lazmx = -inf; if(l == r) { tree[rt].sum = tree[rt].max = tree[rt].min = a[l]; tree[rt].smx = -inf,tree[rt].smn = inf; tree[rt].mxCnt = tree[rt].mnCnt = 1; return ; } int mid = (l + r) >> 1; build(l,mid,rt << 1); build(mid + 1,r,rt << 1 | 1); pushup(rt);}inline void updateSum(int rt,int val,int l,int r){ tree[rt].sum += (r - l + 1ll) * val; tree[rt].max += val,tree[rt].min += val; if(tree[rt].lazmn != inf) tree[rt].lazmn += val; if(tree[rt].lazmx != -inf) tree[rt].lazmx += val; if(tree[rt].smn != inf) tree[rt].smn += val; if(tree[rt].smx != -inf) tree[rt].smx += val; tree[rt].lazsm += val;}inline void updateMin(int rt,int val){ if(tree[rt].max <= val) return ; tree[rt].sum += (val - tree[rt].max) * tree[rt].mxCnt; if(tree[rt].smn == tree[rt].max) tree[rt].smn = val; if(tree[rt].min == tree[rt].max) tree[rt].min = val; tree[rt].lazmx = min(tree[rt].lazmx,val),tree[rt].max = val,tree[rt].lazmn = val;}inline void updateMax(int rt,int val){ if(tree[rt].min > val) return ; tree[rt].sum += (val - tree[rt].min) * tree[rt].mnCnt; if(tree[rt].smx == tree[rt].min) tree[rt].smx = val; if(tree[rt].max == tree[rt].min) tree[rt].max = val; tree[rt].lazmn = max(tree[rt].lazmn,val),tree[rt].min = val,tree[rt].lazmx = val;}inline void pushdown(int rt,int l,int r){ int mid = (l + r) >> 1; if(tree[rt].lazsm) { updateSum(rt << 1,tree[rt].lazsm,l,mid); updateSum(rt << 1 | 1,tree[rt].lazsm,mid + 1,r); tree[rt].lazsm = 0; } if(tree[rt].lazmx != -inf) { updateMax(rt << 1,tree[rt].lazmx); updateMax(rt << 1 | 1,tree[rt].lazmx); tree[rt].lazmx = -inf; } if(tree[rt].lazmn != inf) { updateMin(rt << 1,tree[rt].lazmn); updateMin(rt << 1 | 1,tree[rt].lazmn); tree[rt].lazmn = inf; }}inline void modifySum(int rt,int l,int r,int L,int R,int val){ if(L <= l && R >= r) return updateSum(rt,val,l,r); pushdown(rt,l,r); int mid = (l + r) >> 1; if(L <= mid) modifySum(rt << 1,l,mid,L,R,val); if(R > mid) modifySum(rt << 1 | 1,mid + 1,r,L,R,val); pushup(rt);}inline void modifyMin(int rt,int l,int r,int L,int R,int val){ if(tree[rt].max <= val) return ; if(L <= l && R >= r && tree[rt].smx < val) return updateMin(rt,val); pushdown(rt,l,r); int mid = (l + r) >> 1; if(L <= mid) modifyMin(rt << 1,l,mid,L,R,val); if(R > mid) modifyMin(rt << 1 | 1,mid + 1,r,L,R,val); pushup(rt);}inline void modifyMax(int rt,int l,int r,int L,int R,int val){ if(tree[rt].min >= val) return ; if(L <= l && R >= r && tree[rt].smn > val) return updateMax(rt,val); pushdown(rt,l,r); int mid = (l + r) >> 1; if(L <= mid) modifyMax(rt << 1,l,mid,L,R,val); if(R > mid) modifyMax(rt << 1 | 1,mid + 1,r,L,R,val); pushup(rt);}inline int querySum(int rt,int l,int r,int L,int R){ if(L <= l && R >= r) return tree[rt].sum; pushdown(rt,l,r); int mid = (l + r) >> 1,res = 0; if(L <= mid) res += querySum(rt << 1,l,mid,L,R); if(R > mid) res += querySum(rt << 1 | 1,mid + 1,r,L,R); return res;}inline int queryMax(int rt,int l,int r,int L,int R){ if(L <= l && R >= r) return tree[rt].max; pushdown(rt,l,r); int mid = (l + r) >> 1,res = -inf; if(L <= mid) res = max(res,queryMax(rt << 1,l,mid,L,R)); if(R > mid) res= max(res,queryMax(rt << 1 | 1,mid + 1,r,L,R)); return res;}inline int queryMin(int rt,int l,int r,int L,int R){ if(L <= l && R >= r) return tree[rt].min; pushdown(rt,l,r); int mid = (l + r) >> 1,res = inf; if(L <= mid) res = min(res,queryMin(rt << 1,l,mid,L,R)); if(R > mid) res = min(res,queryMin(rt << 1 | 1,mid + 1,r,L,R)); return res;}signed main(){ ios::sync_with_stdio(0),cin.tie(0),cout.tie(0); cin >> n; for(int i = 1;i <= n;i++) cin >> a[i]; build(1,n,1); cin >> m; while(m--) { cin >> opt >> l >> r; if(opt == 1) { cin >> x; modifySum(1,1,n,l,r,x); } if(opt == 2) { cin >> x; modifyMax(1,1,n,l,r,x); } if(opt == 3) { cin >> x; modifyMin(1,1,n,l,r,x); } if(opt == 4) cout << querySum(1,1,n,l,r) << '\n'; if(opt == 5) cout << queryMax(1,1,n,l,r) << '\n'; if(opt == 6) cout << queryMin(1,1,n,l,r) << '\n'; }}Seg Beats 其实不止可以给线段树用,它实际上是一种把区间最值操作转化为区间加减的 Trick,因此,面对带插入的问题,你甚至可以在平衡树上跑这个东西,只是代码还能再多 100 多行。
10.线段树合并
就是把两棵线段树所维护的信息合并起来。
显然,静态的线段树合并没有什么实际意义,最好的方法就是全部拉出来重构。
所以我们常常是合并动态开点的线段树。
过程和 FHQ Treap 差不多,如果遇到 树中有一个结点而 树中没有,则直接返回这个结点。
如果已经递归到叶子结点,就合并他们的信息(就是对两个叶子结点进行一次维护的操作),然后返回。
代码分在线和离线两种。
先讲离线的,就是直接将 树的信息合并到 树中。但是后面就不能有修改操作了,否则会导致信息错乱。
代码很简单:
inline int merge(int L,int R,int l,int r){ if(!L || !R) return L | R; if(l == r) { tree[L].mx += tree[R].mx; tree[L].maxid = l; return L; } int mid = (l + r) >> 1; lson(L) = merge(lson(L),lson(R),l,mid); rson(L) = merge(rson(L),rson(R),mid + 1,r); pushup(L); return L;}在线的做法就是每次合并就新开一个点,把两棵线段树的信息都合并进去,缺点就是空间占用太大了。
11.线段树分裂
对于一个无序的序列,分裂显然没有什么用,所以我们一般分裂的是权值线段树。
时刻记住,线段树是 Leafy Tree,所以单独一个区间会分裂出来一条链。
但是我觉得这玩意好像考的很少,感觉还是合并会多一点。
具体操作就先分三类讨论:
- 现在的区间和分裂区间无交集:直接返回
- 现在的区间和分裂区间有交集:新建结点,往子结点走
- 被完全包含:断开原有的边,接到新树下方
12.线段树优化建图
虽然连边是 的无法优化了,但是有的时候,边的数量会很多,这个时候就该优化建图了。
线段树可以处理 向 连边的问题,这个区间可以是单点。
我们构建两个线段树,叶子结点是给你的点,第一棵从父亲向儿子连边,叫做出树,第二棵从儿子连向父亲,叫做入树。两棵树可以共用叶子结点,也可以分别建,再从出树到入树对应连边。
这些点都是多加的虚点,注意在跑图论算法的时候不要计入贡献。
分几种情况:
(1) 单点连区间
我们在入树中找到单点,再将连的区间按照线段树的套路拆成出树上的 个区间,然后单点连向拆分出的区间。
(2) 区间连单点
把上面的出入反一下。
(3) 区间连区间
我们新建一个虚点 ,同样的拆分区间。入树中的点连向 , 再连向出树中的点。
可以发现,边的数量是 的,时间复杂度可以优化为 。
13.线段树分治
我觉得这个东西还不如叫时间分治,只是有区间操作用线段树维护会更快一点。
实际上就是一个操作,直接操作是容易的,但是难以删除,并且对时间轴上的一个区间生效,那我们就可以按照线段树的方式拆分区间,在 个区间上打上标记,并在叶子结点计算答案。
实现上,我们线段树每个结点是一个 vector,存储这个结点该加入的操作。我们先添加操作,然后遍历整棵线段树,进入一个结点就加入所有操作,遍历到叶子结点的时候返回答案,离开一个结点就撤销加入的操作。
因此,我们就可以维护出现的时间,将定点删除操作转化为撤销操作。维护你需要的操作还需要其他东西,比如线性基,并查集等,并且你得考虑是否能方便的撤销。
14. 猫树 & 猫树分治
猫树
有的时候我们要维护的信息既不满足可重复贡献性,直接合并的复杂度也无法接受。这个时候就应该用猫树了。
猫树是一种静态的线段树,空间复杂度为 ,但是能做到每次查询仅需要 次合并。
具体来讲,假设一个结点维护的是 的信息并,那我们额外维护 的后缀和与 的前缀和。
然后,对于一个区间 的查询,我们可以找到结点 与结点 的 LCA,设其为 。显然,,我们只需要将 中 与 的信息合并起来就行。
我们惊奇的发现,如果用堆式建树,那么 LCA 的编号就是两个叶子结点编号的 LCP,即 x >> bits[x ^ y],其中 x,y 是两结点编号,bits[x] 表示 。
然后对于 的情况特判就行。
猫树分治
你可以把这玩意看作在序列上跑的点分治。
Eg. Luogu P6240 好吃的题目↗
题意:对序列 的一个区间 内所有物品 做容量为 的 01 背包。
考虑分治,我们把询问分成两类:跨过中点的与没跨过中点的。没跨过中点的直接下传去下一层做,重点看跨过中点的。
我们发现,这和上面写的猫树的一次查询很像,于是我们考虑将一层视作一个结点,求 的后缀背包与 的前缀背包,然后进行合并。
但是又有个问题,这里不支持 的背包合并。但是我们发现,背包问题等价于 卷积,并且我们只需要求特定的一项的值,于是可以用卷积的定义来计算,。
时间复杂度是 ,主定理算出来是 ,空间复杂度是 。
可以直接用猫树做在线的,但空间会多一个 。
Addition.一些小 Tricks
线段树维护操作序列
就是把操作序列抽象成普通序列,然后放到线段树上维护。
只要这个操作序列可以抽象成幺半群,那就可以用线段树维护。
我们用线段树维护区间乘积,对于 操作,把 处的值修改为 ,对于 操作,把 处的值修改为 。
查询都可以不写,直接求 tree[root] 处的值就好了。
二维偏序 & 树套树
因为本人不太喜欢 CDQ 分治,所以决定在这里就写二维偏序。
如果是离线的二维数点,我们可以直接扫描线 + 树状数组来解决,如果值域太大,也可以用主席树解决,离散化后对每一个横坐标新建一个版本并进行更改。查询可以直接用主席树惯用套路,用右横坐标的版本减去左横坐标的前一个版本来构建区间的树,然后在上面跑纵坐标的区间查询就行。
但是放到动态呢?你可以说加个时间维度,跑三维偏序,但我就喜欢用纯 DS。
我们可以用树套树维护这个,外层树可以是树状数组这种方便查询前缀的 DS,开不下可以换成线段树,内层一般不会让你开下第二个树状数组,于是我们可以选择权值树状数组或者平衡树。
两个做比较的话,就是里面放线段树的空间会大一点,平衡树的时间会大一点。
然后线段树同样可以作为外层树,但是就必须对整条链进行操作,不能打标记。